Decision Trees#
With the help of Secret Sharing, a secure multi-party computation technique,
SecretFlow implements provably secure gradient boosting model
Xgb()
to support both regression and binary classification machine learning tasks.
Dataset Settings#
vertically partitioned dataset:
samples are aligned among the participants
different participant obtains different features
one participant owns the label

XGBoost Training Algorithm#
Algorithm details can be found in the official documents. The main process of building a single tree is as follows:
Statistics calculating: calculate the first-order gradient \(g_{i}\) and second-order gradient \(h_{i}\) for each sample with current prediction and label, according to the definition of loss function.
Node splitting: enumerates all possible split candidates and choose the best one with the maximal gain. A split candidate is consisted of a split feature and a split value, which divides the samples in current node \(I\) into two child nodes \(I_{L}\) and \(I_{R}\), according to their feature values. Then, a split gain is computed with the following formula:

where \(\lambda\) and \(\gamma\) are the regularizers for the leaf number and leaf weights respectively. In this way, we can split the nodes recursively until the leaf.
Weight calculating: calculate the weights of leaf nodes with the following formula:

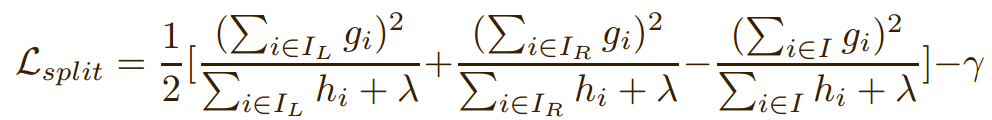
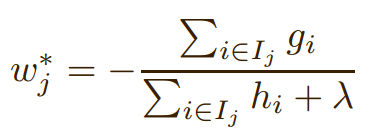
Regression and classification share the same training process except:
they employs different loss functions, i.e. MSE for regression and Logloss for classification.
classification executes an extra sigmoid function to transform the prediction into a probability.
SS-XGB Training#
SS-XGB Xgb() use secret sharing to compute the split gain and leaf weights.
In order to implement a secure joint training, we replace all the computations with secret sharing protocols, e.g. Addition, Multiplication, etc. In addition, we have to take special care to accumulate the gradients without leaking out the feature partial order of samples.
This problem can be solved by introducing an indicator vector 𝑆.

The samples to be accumulated is marked as 1 in 𝑆 and 0 otherwise. To preserve privacy, the indicator vector also transformed to secret shares. In this way, the sum of the gradients of the samples can be computed as the inner product of the indicator vector and the gradient vector, which can be securely computed by secret sharing protocols.
Similarly, the indicator trick can be used to hide the instance distribution on nodes. Refer to our paper Large-Scale Secure XGB for Vertical Federated Learning for more details about SS-XGB algorithm and security analysis.
Example#
A local cluster(Standalone Mode) needs to be initialized as the running environment for this example. See Deployment and refer to the ‘Cluster Mode’.
For more details about the APIs, see Xgb()